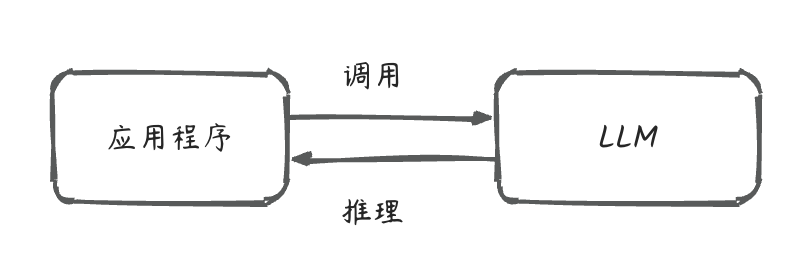
LLM应用程序在最初的设想中是非常简单的,通过调用一次API即可完成相应的任务。这些任务有:翻译、问答、搜索、情感分类等等。对于应用测来说,它仅仅就是一次外部工具的调用,完全不需要考虑使用任何框架。
以至于在LangChain/LlamaIndex这类框架出现后,大家开始觉得有点蒙,它们用来解决什么问题?
事情的变化要从几个方面说起。
一、Prompt=业务,让管理prompt成为必要
LLM随着规模的扩大,“涌现”出了模型本身并没有的能力, 换句话说,这些能力并不是在做模型时提前设计好的。这种随着规模扩大,而出现“能力涌现”的事情,我们称之为:scale law(规模定律)。而这种能力是通过prompt(提示词)引导出来的。大家发现,即使是做同一样的任务,使用不同背景、约束、流程的prompt,就会产生了不同的效果,甚至某些关键词汇的出现,会让结果有很大的不同。大家常常自嘲调模型参数犹如炼丹,但其实调prompt也差不多。
一个基于AI的业务,最大的事就是稳定性,所以大家把prompt做成完成不同业务的稳定模版,就成了AI应用开发必须要做的事情。当然了,prompt的管理不仅包含模版管理,一般来说,prompt在上线之前是需要经过迭代更新、测试和审核的。
二、Agent需要不同节点的记忆能力
在和LLM进行对话时,会发现它会知道你之前聊了什么,然后就同一个话题给你生成内容。这并非LLM本身的能力,而是LLM产品在LLM之上提供了记忆功能,将历史聊天记录每次发给LLM,这种对话称为多轮对话。看起来也挺简单,不过考虑到LLM的API层面都未提供记忆功能,所以这块还得自己手动实现。
多轮对话容易解决,不过要做对话产品,还需要实现完整的对话线管理。举个栗子,用户A在和某Agent进行对话时,会先开启一个话题,如:
User:帮我讲个笑话。
Agent:从前有个A…
User:讲个苏联笑话。
Agent:…
此时,用户A在和Agent进行一场多轮对话。10天后,用户A又重新翻出这场对话,继续发起聊天。作为Chat Agent,肯定是需要重新拉取出这场对话的上下文的。同时也得知道,用户A可能在10天内,也发起过新的其他对话。这些对话线,都是需要记忆的。现在,我们就知道了对话产品的对话线关系大概是这样的:
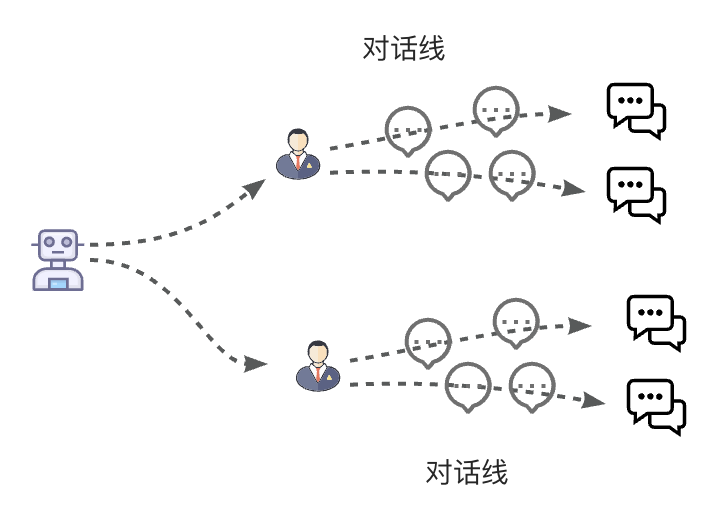
即:Agent对应多个User,每个User有多个会话Session,每个Session有多轮对话记录。在一个多用户对话Agent应用里面,就需要手动管理好这些对话线。
关于记忆的另外一块是关于RAG的。图灵大师说过:不犯错的智能不是真的智能。LLM经常有幻觉问题,缓解办法有:微调、调Prompt等等。但这种解法有些弊端,微调可以理解为轻量级训练,它的成本低于训练,但也要花很多资源和时间,另外它的实时性没办法保证。调Prompt的问题是,它基本只能挖掘LLM的潜在思维能力和workflow,但不能赋予LLM新知识。一个较好的办法是:RAG。RAG翻译过来是:检索增强生成。简单理解就是:引入外部知识,将其向量化并存储到数据库。在检索时,先语义查询出相似知识片段,再让LLM进行包装形成最终回复。
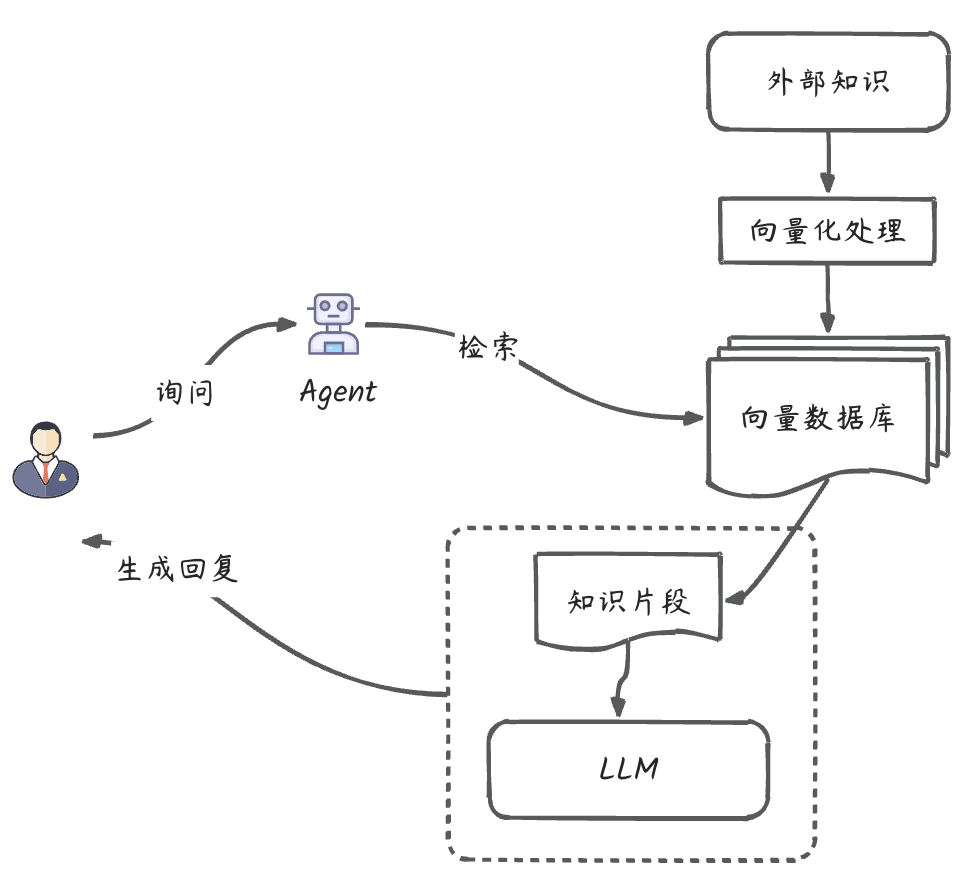
在这个过程里面,向量存储和检索,是外挂知识库的常见功能。这类高频操作,最好是使用框架来实现。
三、多Agent的交互与协作
在一个LLM应用里面,完成一个业务动作可能需要很多子步骤,我们会面临传统互联网架构中的拆分问题。单Agent都能做的事情为何要拆成多Agent的?收益在哪儿?这个问题放在传统互联网架构中也是很常见的。一般来说,业务复杂度是衡量是否要拆分的核心因素(其次才是性能)。一个复杂的业务,往往可以拆分成很多步骤/动作,而且LLM中的复杂业务可能连这些动作都是动态规划的(比如A完成该业务需要3个动作,B需要5个)。这就和传统互联网架构很不一样。除了要抽象出Agent这一层代码结构之外,还要考虑到如何让Agent能进行自我规划,并和其他Agent交互/协作。可以想象,处理某件“事”的都是一个个“小人儿”,这些“小人儿”拥有自己的判断及团队协作能力。在斯坦福小镇这个开源项目中,就有25个这种“小人儿”活动在一个虚拟村落中,大家有独立生活,也有协作治理。再比如大名鼎鼎的多智能体框架MetaGPT,它号称可以实现“老板的一句话需求”。它里面包含了产品经理 / 架构师 / 项目经理 / 工程师的角色,这些角色实际上也就是Agent,它们通过协作来完成一个软件的研发。这会是未来LLM应用开发的常规模式。
四、关于LLM应用开发框架的实践体感
聊完以上几点,会发现LLM应用的侧重点在于Prompt管理和Agent的治理,那么LLM应用开发框架也得相应提供这样的抽象能力。不仅如此,由于多Agent协作的广泛应用,大家其实也需要路由、鉴权、调用链监控、token安全/流量/计费等能力,这和传统互联网架构也类似。不过按照目前云原生的发展情况,这块肯定还是会被云厂商接管,它可以不用属于开发框架。
由于LLM应用开发=Agent应用开发,是大家的普遍共识,那么LLM应用开发的核心必然是要满足对Agent核心组件的赋能。业界有个很出名的公式:Agent=大模型+记忆+主动规划+工具使用。可以看出来,前文中聊到的一些点,正是这个公式所覆盖的。
最后说说我对目前一些常见的开发框架的感觉吧(包括但不限于LangChain、LlamaIndex等)。
在LLM Agent应用开发的实践中,感觉很多框架看起来很细,但抽象的还是不够,总结起来就是:全面但不灵活。未来框架可能会有两大流派:体系派、工具派,而目前的情况是半体系+零碎工具。
我认为 Agent 开发框架还未迎来终局一战。yy下可能的战斗场面:大东山上,N大宗师(框架)混战只剩下庆帝,但最终被蒙眼的五竹不讲武德揭开眼罩镭射掉😎…



